평균모멘텀스코어는 원래 책에서 월말 기준으로 백테스트 시점과의 차를 평균해서 구했습니다.
어차피 추세를 이용하는거니깐 월평평균을 하는게 더 정확하지 않을까 하는 의문이 들었습니다.
그래서 월별평균으로 한 평균모멘텀스코어와 오리지날을 비교해 보도록 하겠습니다.
백테스트 시작기간은 2000년 1월 2일부터 2024년 2월 29일까지입니다.
| 구 분 (Moment기간) |
3개월 | 6개월 | 9개월 | 12개월 | ||||
| CAGR | MDD | CAGR | MDD | CAGR | MDD | CAGR | MDD | |
| SPY | 10.2 | -51.5 | 10.2 | -51.5 | 10.2 | -51.5 | 10.2 | -51.5 |
| SPY+TLT (Original) |
9.9 | -39.1 | 10.1 | -37.8 | 9.9 | -36.0 | 9.9 | -34.9 |
| SPY+TLT (월평균) |
9.7 | -38.2 | 10.1 | -36.5 | 9.9 | -35.0 | 9.8 | -33.9 |
월평균으로 했을때 Original과 비교해서 CAGR은 거의 비슷하게 나오지만 전체적으로 MDD 는 약간 더 낮게 나오네요.
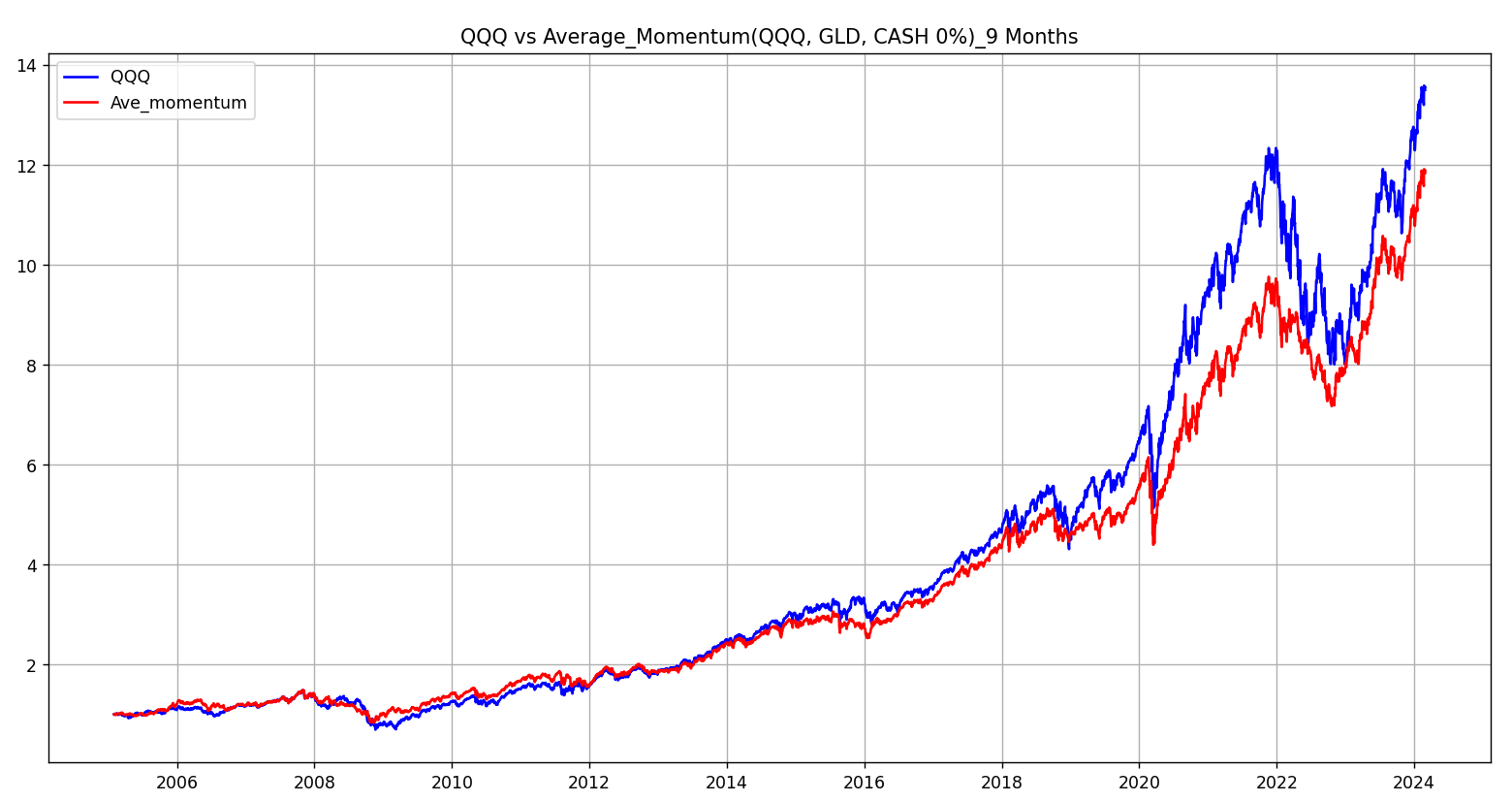
이번에는 QQQ와 GLD를 비교해서 분석해 보겠습니다.
백테스트 시작기간은 GLD가 2004년 11월부터 데이터가 있어서 2005년 1월 2일부터 2024년 2월 29일까지 입니다.
| 구 분 (Moment기간) |
3개월 | 6개월 | 9개월 | 12개월 | ||||
| CAGR | MDD | CAGR | MDD | CAGR | MDD | CAGR | MDD | |
| QQQ | 14.7 | -51.2 | 14.7 | -51.2 | 14.7 | -51.2 | 14.7 | -51.2 |
| QQQ+GLD (Original) |
15.9 | -38.9 | 14.7 | -36.0 | 14.3 | -36.7 | 14.3 | -39.4 |
| QQQ+GLD (월평균) |
14.2 | -49.2 | 13.7 | -43.0 | 13.9 | -43.6 | 14.2 | -43.7 |
QQQ와 GLD를 비교했을 때는 월평균이 Original에 비교해서 CAGR은 낮고, MDD는 더 많이 떨어지네요. 이럴거면 굳이 코드를 추가해서 월평균을 할 필요는 없을 것 같습니다.
그런데 이유가 뭘까요?
주식의 등락폭은 매월 1일~말일로 끊어서 발생하지 않아서 그런게 아닐까 합니다. 이유야 어떻든 수치가 이렇게 나오면 원래 책에서 나오는 방법대로 투자하는 것이 유리할 것 같습니다.
시간은 좀 걸렸지만, 확인을 할 수 있어서 다행입니다.
아래는 전체 코드입니다.
import pandas as pd
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
from datetime import datetime
import matplotlib.pyplot as plt
pd.options.display.float_format = '{:,.2f}'.format
p1 = 'QQQ'
p2 = 'GLD'
현금비율 = 0 #현금비율
#초기 투입자금
주식자금 = 500
채권자금 = 500
현금자금 = 0
#평균모멘텀스코어 기간
moment_months = 9
start = datetime(2005, 1, 1)
end = datetime(2024, 2, 29)
df1 = pdr.get_data_yahoo(p1, start, end)
print(df1)
df2 = pdr.get_data_yahoo(p2, start, end)
print(df2)
df_o = pd.DataFrame({'p1': df1['Adj Close'], 'p2' : df2['Adj Close']})
df_o.set_index(df1.index)
df_o.dropna(inplace=True)
# 월별 주가평균
def monthly_mean(df_o):
df = df_o.groupby(by=[df_o.index.year, df_o.index.month]).mean()
return df
# 월말 날짜만 가져오기
def get_monthly_end(df_d):
df_d['Odate'] = df_d.index
df = df_d.groupby(by=[df_d.index.year, df_d.index.month]).last()
df.set_index('Odate', inplace=True)
return df
#평균모멘텀스코어 구하기
def score(df_d, moment_months):
mm = int(moment_months)
df_m = monthly_mean(df_d)
df = get_monthly_end(df_d)
li_score = []
for i in range(len(df_m)):
if i < 11:
li_score.append(0)
else:
val = 0
for m in range(1, mm+1):
if df_m['p1'].iloc[i] - df_m['p1'].iloc[i - m] > 0:
val += 1
li_score.append(val / mm)
df['평균모멘텀스코어'] = li_score
return df
#MDD 구하기
def get_mdd(col):
window = 252 #1년간 영업일을 252일로 가정
peak = col.rolling(window, min_periods=1).max() #기간 동안에 최고 주가(결과값은 시리즈로 나옴)
drawdown = col/peak - 1 #최고치 대비 현재 주가가 얼마나 하락했는지 구함
연도별mdd = drawdown.rolling(window, min_periods=1).min()#"최고치-현재주가" 중 가장 작은값을 구함
mdd = 연도별mdd.min()
return mdd
#백테스트
def back_test(df_d, moment_months, 현금비율, 주식자금, 채권자금, 현금자금):
df = score(df_d, moment_months)
주식 = []
주식수 = []
채권 = []
채권수 = []
현금 = []
합계 = []
for i in range(len(df)):
if i == 0:
주식.append(주식자금)
주식수.append(주식자금/df['p1'].iloc[i])
채권.append(채권자금)
채권수.append(채권자금/df['p2'].iloc[i])
현금.append(현금자금)
합계.append(주식[i]+채권[i]+현금[i])
else:
합계.append(주식수[i-1]*df['p1'].iloc[i] + 채권수[i-1]*df['p2'].iloc[i] + 현금[i-1]*(1+0.03/12))
주식.append(합계[i]*(1-현금비율)*df['평균모멘텀스코어'].iloc[i])
현금.append(합계[i]*현금비율)
채권.append(합계[i]-주식[i]-현금[i])
주식수.append(주식[i]/df['p1'].iloc[i])
채권수.append(채권[i]/df['p2'].iloc[i])
df['주식'] = 주식
df['채권'] = 채권
df['현금'] = 현금
df['합계'] = 합계
df['주식수'] = 주식수
df['채권수'] = 채권수
# 월말 데이터를 일별 데이터로 만들기
df = pd.merge(df_o[['p1', 'p2']], df[['평균모멘텀스코어', '주식', '채권', '현금', '합계', '주식수', '채권수']],
left_index=True, right_index=True, how='outer')
df.fillna(0, inplace=True)
for s in range(1, len(df)):
if df['합계'].iloc[s] == 0:
df['주식수'].iloc[s] = df['주식수'].iloc[s-1]
df['채권수'].iloc[s] = df['채권수'].iloc[s-1]
df['주식'].iloc[s] = df['p1'].iloc[s] * df['주식수'].iloc[s]
df['채권'].iloc[s] = df['p2'].iloc[s] * df['채권수'].iloc[s]
df['현금'].iloc[s] = df['현금'].iloc[s-1]
df['합계'].iloc[s] = df['주식'].iloc[s] + df['채권'].iloc[s] + df['현금'].iloc[s]
df['평균모멘텀스코어'].iloc[s] = df['평균모멘텀스코어'].iloc[s-1]
# 합계열에서 0이 아닌 숫자가 나오면 행삭제
df.drop(df[df['합계']==0].index, inplace=True)
# 2가지 자산의 누적수익률을 비교하기 위해 백분율로 표현
df['주가백분율'] = df['p1'] / df['p1'].iloc[0]
df['전략백분율'] = df['합계'] / df['합계'].iloc[0]
#CAGR
diff = df.index[-1].year - df.index[0].year
cagr_etf = (df['주가백분율'].iloc[-1] / df['주가백분율'].iloc[0]) ** (1 / diff) - 1
cagr_전략 = (df['전략백분율'].iloc[-1] / df['전략백분율'].iloc[0]) ** (1 / diff) - 1
cagr = f'CAGR(ETF) : {round(cagr_etf, 3)} / CAGR(전략) : {round(cagr_전략, 3)}'
print(cagr)
#MDD구하기
mdd_etf = get_mdd(df['p1'])
mdd_전략 = get_mdd(df['합계'])
mdd_t = f'MDD(ETF) : {round(mdd_etf,3)} / MDD(전략) : {round(mdd_전략,3)}'
print(mdd_t)
#엑셀파일로 만들기
df.to_excel(f'평균모멘텀스코어 백테스트({p1}, {p2}, CAGR {round(cagr_전략*100,1)} '
f'MDD {round(mdd_전략*100,1)})(월별평균).xlsx')
#그래프로 표현하기
plt.rcParams['figure.figsize'] = (16, 9)
plt.plot(df.index, df['주가백분율'], color='blue', label=p1)
plt.plot(df.index, df['전략백분율'], color='red', label='Ave_momentum')
plt.grid(True)
plt.legend(loc='best')
plt.title(f'{p1} vs Average_Momentum({p1}, {p2}, CASH {int(현금비율*100)}%)_{moment_months} Months')
plt.show()
return df
back_test(df_o, moment_months, 현금비율, 주식자금, 채권자금, 현금자금)728x90
'파이썬(Python) > 파이썬으로 투자실험' 카테고리의 다른 글
| 자산분배 백테스트(주식+채권 vs 주식+현금) (0) | 2024.03.25 |
|---|---|
| 파이썬으로 CAGR과 MDD 구현하기(Pandas) (0) | 2024.03.20 |
| 포트폴리오에 현금을 포함 시킬 때 CAGR과 MDD 결과 (0) | 2024.03.16 |
| 평균모멘텀스코어 개월 수에 따른 CAGR과 MDD 분석 (3) | 2024.03.13 |
| SPY & TLT 5:5 투자와 평균모멘텀스코어로 투자 시 CAGR 및 MDD 비교(정적 배분 투자 vs 동적 배분 투자) (1) | 2024.03.11 |



댓글