
TV를 보다가 갑자기 "내 블로그가 몇 번째로 검색이 될까?" 하는 궁금증이 생기기 시작했습니다.
갑자기 생긴 궁금증은 해결이 될 때까지 저를 가만두지 않았습니다.
결국 노트북으로 와서 코딩을 시작했습니다.
우선 어떻게 검색을 할 것인지 구상을 하고, 네이버에 직접 키워드를 입력해 보았습니다.
우리나라에서 가장 많이 쓰는 네이버 검색창을 기준으로 만들기로 했습니다.
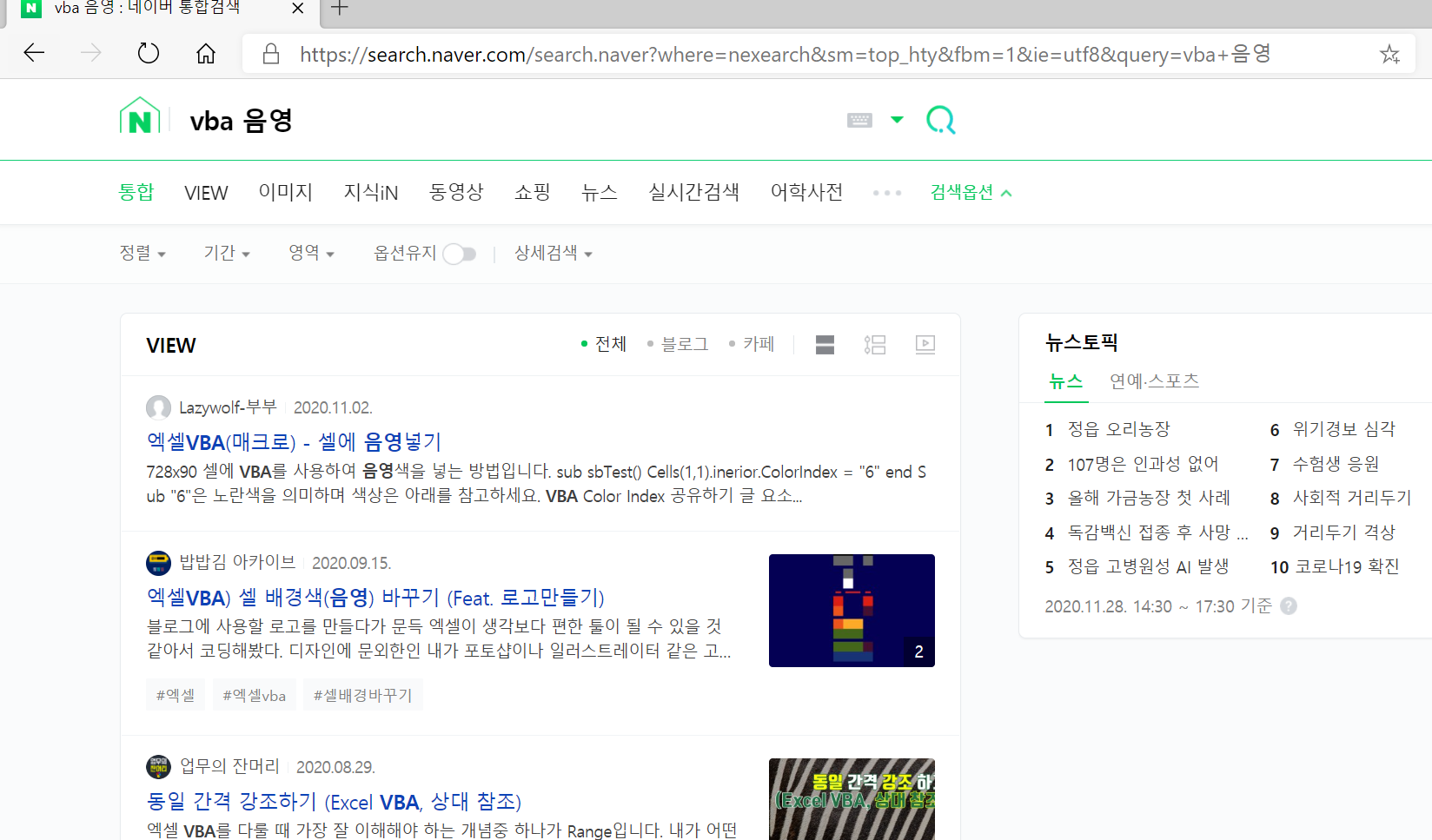 |
제 블로그가 맨 위에 검색이 되네요. ㅎㅎㅎ
우선 주소창이 어떻게 바뀌는지 관찰하고, 'F12'를 눌러서 'html'를 살펴보았습니다.
 |
생각보다 html 코드가 간단해서 금방 작성할 수 있었습니다.
|
import requests from bs4 import BeautifulSoup |
모듈은 requests와 bs4의 BeautifulSoup 만 있으면 되겠네요.
| myblog = 'dotsnlines.tistory.com' |
내 블로그가 몇 번째 검색되는지 알기위해 내 블로그 주소를 넣고 'myblog'라는 변수로 지정합니다.
|
url = 'https://search.naver.com/search.naver?display=10&f=&filetype=0&page=2&query=' keyword = 'vba 음영' url_a = '&research_url=&sm=tab_pge&start=' url_b = '&where=web' |
url은 구조상 4개로 나눴습니다. 엄밀히 말해서 page까지 5개네요.
keyword는 제가 검색할 단어를 넣는 변수입니다.
|
for No in range(0,100): result = requests.get(url+keyword+url_a+str(No*10+1)+url_b) bs_obj = BeautifulSoup(result.content,'html.parser')
div = bs_obj.find('div',class_='api_subject_bx') ul = div.find('ul') lis = ul.find_all('li')
for num, li in enumerate(lis): a = li.find('a')['href'] blog = a.split('/') if blog[2] == myblog: print(str(No*10+num+1)+'번째로 검색 되었습니다'+str(a)) |
for문을 써서 1000 page 까지 검색을 하고, 각 태그를 순서대로 뽑아 냈습니다.
각 페이지별로 li 태그 속의 href 속성을 가져오고 제 블로그의 주소와 비교해서 같으면 몇 번째로 검색이 되었는지 프린트 합니다.
| print('검색이 완료 되었습니다.') |
천개의 검색항목을 다 검색하면 완료되었다고 프린트 됩니다.
이제 한 번 실행시켜 볼까요?
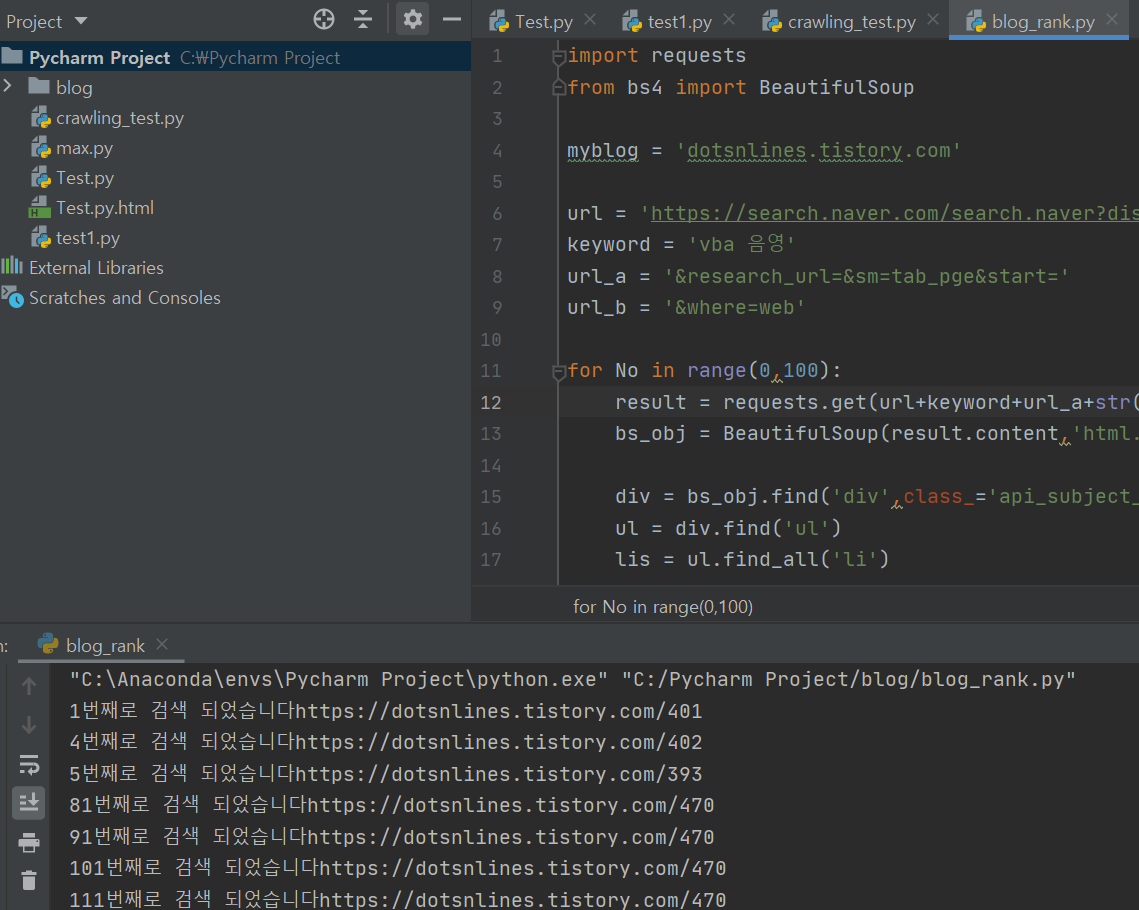
역시나 검색이 잘 되네요. ㅎㅎㅎ
생각보다 너무나 간단하게 만들었네요. 우리 초딩아들도 할 수 있겠어요.
다음 포스트에는 이번에 만든 코드를 가지고 실행파일(exe)을 만들어 보겠습니다.(우리 마눌님도 사용하셔야 하기 때문에...)
혹시나 파이썬이 궁금하시면 비전공자 비관련직 40대 컴맹아저씨의 눈 높이로 제 블로그에 하루에 하나씩 공개되오니 참고하세요.
←블로그 좌측메뉴 파이썬 코너에 정리해 두었습니다.
전체 코드는 아래와 같습니다.↓
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import requests
from bs4 import BeautifulSoup
myblog = 'dotsnlines.tistory.com'
url = 'https://search.naver.com/search.naver?display=10&f=&filetype=0&page=2&query='
keyword = 'vba 음영'
url_a = '&research_url=&sm=tab_pge&start='
url_b = '&where=web'
for No in range(0,100):
result = requests.get(url+keyword+url_a+str(No*10+1)+url_b)
bs_obj = BeautifulSoup(result.content,'html.parser')
div = bs_obj.find('div',class_='api_subject_bx')
ul = div.find('ul')
lis = ul.find_all('li')
for num, li in enumerate(lis):
a = li.find('a')['href']
blog = a.split('/')
if blog[2] == myblog:
print(str(No*10+num+1)+'번째로 검색 되었습니다'+str(a))
print('검색이 완료 되었습니다.')
|
cs |
'파이썬(Python) > 파이썬 개발' 카테고리의 다른 글
| 파이썬으로 쉽고 빠르게 빈 폴더 찾아서 폴더명 바꾸기 (5) | 2021.10.16 |
|---|---|
| 파이썬으로 여러 폴더 빠르고 쉽게 만들기 (0) | 2021.10.14 |
| 파이썬 - requests를 이용해서 네이버 검색어 자동으로 사진 다운 받기 (0) | 2020.12.27 |
| 파이썬 - 크롤링 쉽게 시작하기 (0) | 2020.12.24 |
| 파이썬 - 네이버 검색어 크롤링 후 검색 항목 개수 자동 확인 (0) | 2020.12.01 |




댓글